This playbook walks you through building an AI-powered cohort analysis system that automatically discovers which customer segments have the highest retention rates. The LangGraph pipeline dynamically analyzes multiple dimensions and delivers AI-generated insights for targeted retention strategies.
Most cohort analysis focuses on time-based groupings - customers acquired in January vs. February vs. March. While these temporal cohorts show overall retention trends, they provide virtually no actionable insights.
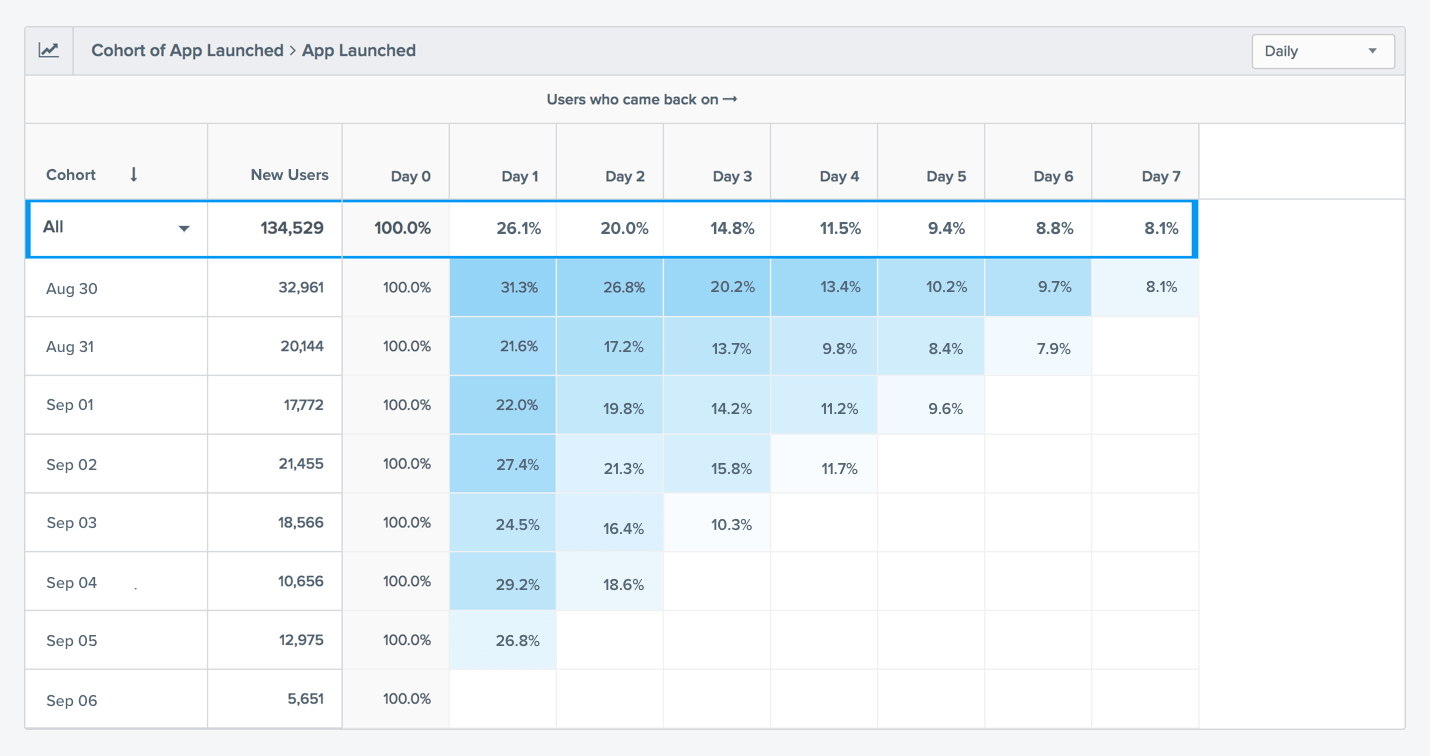
Classical Cohort Matrix from the SaaS company CleverTap
Knowing that "January customers have 35% retention at month 3" tells you nothing about why they're performing poorly, which acquisition channels drove that performance, or what specific actions could improve retention for future cohorts. Time-based analysis is descriptive but not prescriptive.
The real challenge isn't calculating retention rates - it's identifying which customer characteristics actually drive retention differences and translating those insights into actionable strategies.
This playbook demonstrates how to build an AI-powered cohort analysis pipeline that automatically discovers the most important customer segments, analyzes their retention patterns, and generates actionable business insights without manual intervention.
The AI-First Approach to Cohort Discovery
Traditional cohort analysis starts with assumptions about which customer segments matter. AI-powered analysis flips this approach: instead of guessing which dimensions to analyze, we let the system explore all available customer attributes and intelligently select the most promising combinations.
The system catalogs all available customer dimensions, then uses AI to select single and multi-dimensional combinations likely to reveal meaningful retention patterns. This eliminates the guesswork while ensuring comprehensive coverage of your customer base.
Dynamic SQL Generation for Scalable Analysis
Rather than writing separate queries for each cohort dimension, the pipeline generates SQL dynamically based on the discovered attributes. This architectural choice is crucial for scalability—the same code can analyze any customer dimension without modification.
This post is for paying subscribers only
Sign up now and upgrade your account to read the post and get access to the full library of posts for paying subscribers only.