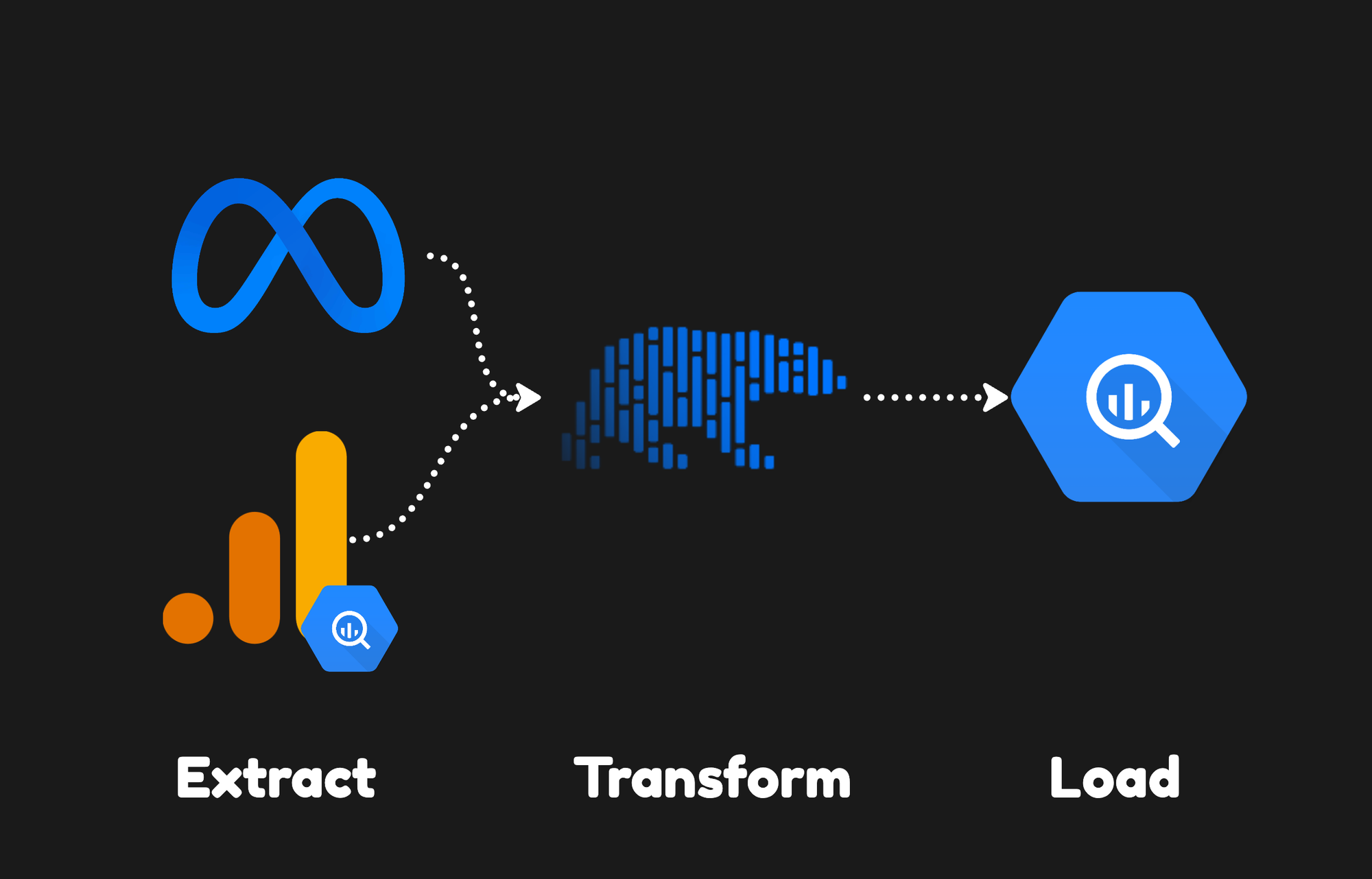
This playbook demonstrates how to build a modern Python data pipeline that extracts Meta Ads data to BigQuery, eliminating CSV exports and creating the warehouse foundation needed to reconcile platform-reported conversions with actual revenue across Meta, GA4, and sales data from a CRM.
Meta Ads data lives in Business Manager. GA4 sessions export to BigQuery. Revenue flows through Stripe or Shopify. These systems don't connect.
Without Meta data in the warehouse, connecting ad spend to actual purchases requires exporting CSVs, joining in spreadsheets, and trusting platform-reported conversions. When Meta reports 500 conversions but Shopify shows 250 orders, there's no systematic way to determine which campaigns drove real revenue versus which benefited from generous attribution windows.
This playbook builds the first piece of your marketing data warehouse - a pipeline that loads Meta Ads data into BigQuery alongside your existing GA4 and revenue data. Once Meta data lands in the warehouse, you can query across platforms, reconcile conversion discrepancies, and build attribution models that connect ad clicks to actual purchases.
The pipeline uses modern Python tooling: Hatch for environment management, Polars for memory-efficient data processing, and Pydantic for configuration validation. The data loads into BigQuery using nested STRUCTs that match GA4's schema design, eliminating the joins that slow down cross-platform queries.
What this playbook builds:
ETL pipeline transforming Meta Ads data into BigQuery nested STRUCTs
Pre-computed metrics (CPM, CTR, CPC, ROAS) calculated during transformation
Partitioned and clustered BigQuery tables for efficient queries
Query patterns for analyzing nested campaign data
What this enables:
Connecting to Meta's API to pull live data (example code included)
Deploying to Cloud Run for automated daily runs
Cross-platform queries joining Meta, GA4, and revenue data
Attribution modeling in future playbooks
Who this is for: Analytics engineers building marketing data warehouses. Data teams that need Meta performance data alongside GA4 sessions and revenue tables for attribution modeling.
Implementation time: 30 minutes to working pipeline with sample data. Add Meta API credentials to connect live data.
Quick Start
# Clone the repo
git clone https://github.com/rabbitengine/playbook-meta-ads-insights
cd playbook-meta-ads-insights
# Run the ETL pipeline
hatch run local
# Query your loaded data
hatch run analyze
The pipeline extracts sample CSV files representing Meta Ads data (campaigns, adsets, ads, creatives, insights), transforms them into nested structures, and loads to BigQuery:
✅ Extracted 5 tables
✅ Transformed to 3 rows
✅ Loaded 3 rows to your-project.marketing_data.meta_ads_insights
🎉 Pipeline completed!
The analyze command queries BigQuery to demonstrate nested field access without joins.
These CSVs simulate the structure returned from Meta's Marketing API. In production, API calls replace CSV reading, but the transformation logic remains identical.
Each row includes the campaign name, adset targeting, creative title, and performance metrics. Query campaign.name directly without joining to a campaigns table.
Building this structure starts with extraction. The pipeline uses Polars to load data efficiently without pandas overhead.
Extracting with Pure Polars
The pipeline uses Polars for memory-efficient data processing without pandas overhead. Polars uses lazy evaluation to defer computation until needed, enabling it to process datasets larger than RAM while pandas loads everything into memory immediately.
Direct CSV reading into Polars DataFrames eliminates intermediate conversions. Memory usage stays low even with millions of rows. Switching to the Meta API means parsing JSON responses directly into Polars - no pandas conversion needed.
With data extracted into separate DataFrames, the next step joins these tables and creates the nested structure BigQuery expects.
Building Nested Structures
Join the dimension tables, then pack related columns into nested STRUCTs. This eliminates the need for joins at query time.
This post is for paying subscribers only
Sign up now and upgrade your account to read the post and get access to the full library of posts for paying subscribers only.